


I am a PhD candidate in Computational Linguistics at Stony Brook University, affiliated with Institute for Advanced Computational Science (IACS). I am fortunate to be advised by Dr. Owen Rambow.
Prior to coming to Stony Brook, I completed a bachelor's degree in Chinese Language and Literature from Hunan University, and a master's degree in Applied linguistics from University of Saskatchewan.
I am a lifelong learner at heart, and as a result my research interests have evolved over time (ever since senior high school back in 2015). Currently, my work focuses on evaluating large (vision/audio/omni) language models from a human-centric perspective, spanning themes such as multi-step and agentic reasoning, human–AI interaction, personalization, multimodality, and post-training. I prioritize research grounded in real-world use cases and open-ended challenges, with an emphasis on scalable and interpretable evaluation methodologies.
I enjoy making new connections, so feel free to reach out to me for any reason and have a coffee chat!
News
-
Jan, 2026: Launched a new Blogs section on my website, featuring various essays (mostly Chinese with English translations by GPT-5.2) I wrote between 2015 and 2019. I hope this will motivate me to write more going forward.
-
Aug, 2025: I started working for Amazon as an Applied Scientist intern, researching Large Audio Language Models for Alexa AI, developing audio integration methods for user satisfaction prediction, and fine-tuning LALMs and Omni models to reduce modality gaps.
-
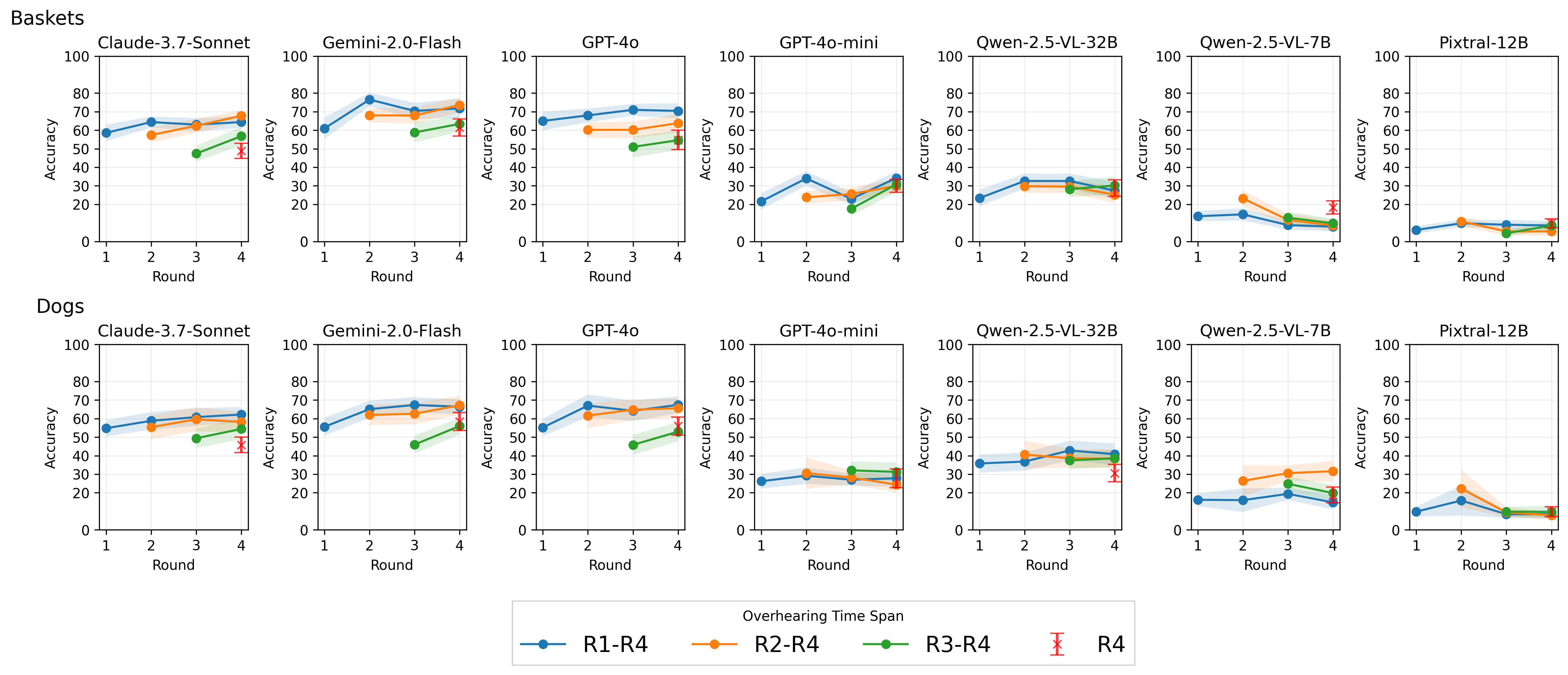
Aug, 2025: My first-authored paper LVLMs are Bad at Overhearing Human Referential Communication has been accepted to EMNLP 2025 (Main).
-
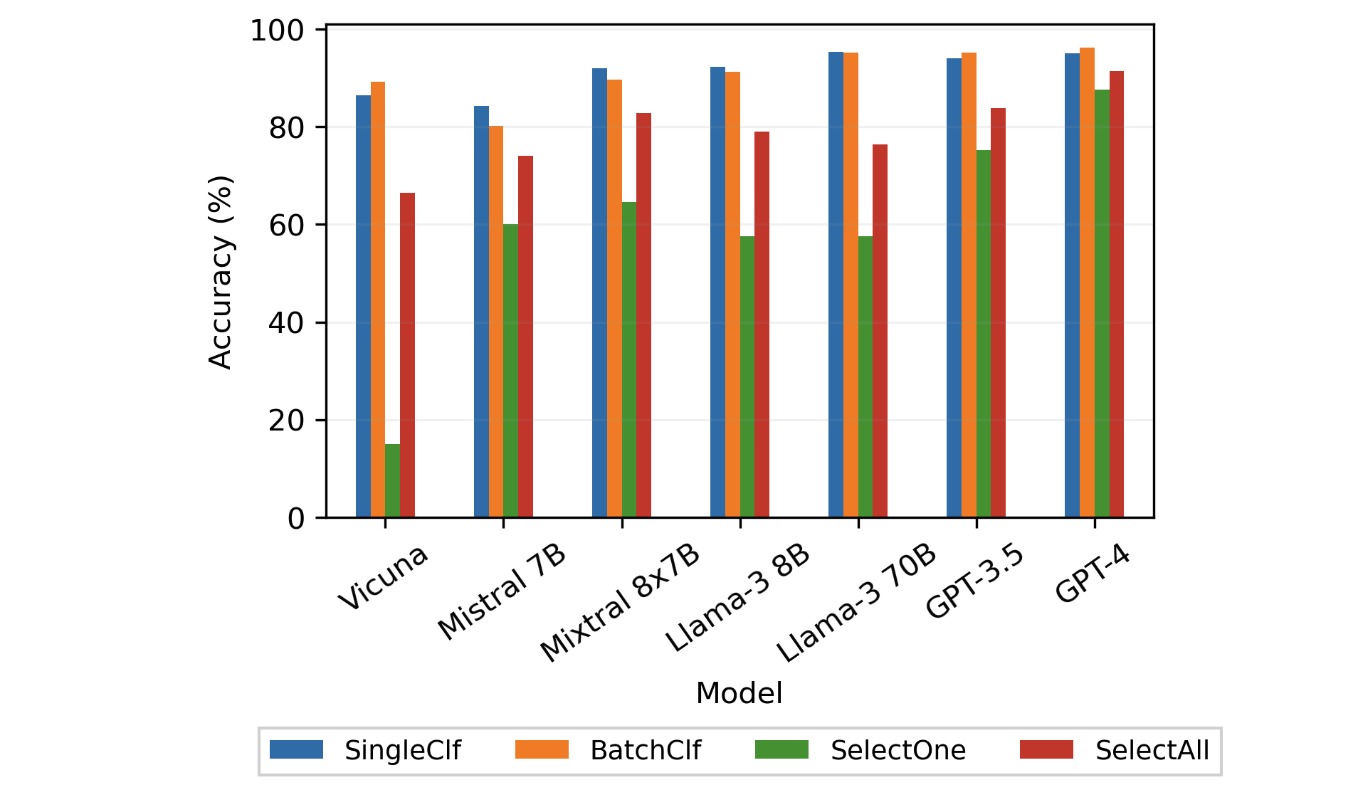
Aug, 2025: My first-authored paper Catch Me If You Can? Not Yet: LLMs Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors has been accepted to EMNLP 2025 (Findings).
-
May, 2025: I started working for Meta as a Software Engineer (Machine Learning) intern. Using Hack (PHP), I built an LVLM-based agentic workflow for trend detection, validation, magnitude labeling, and post content quality rating.
-
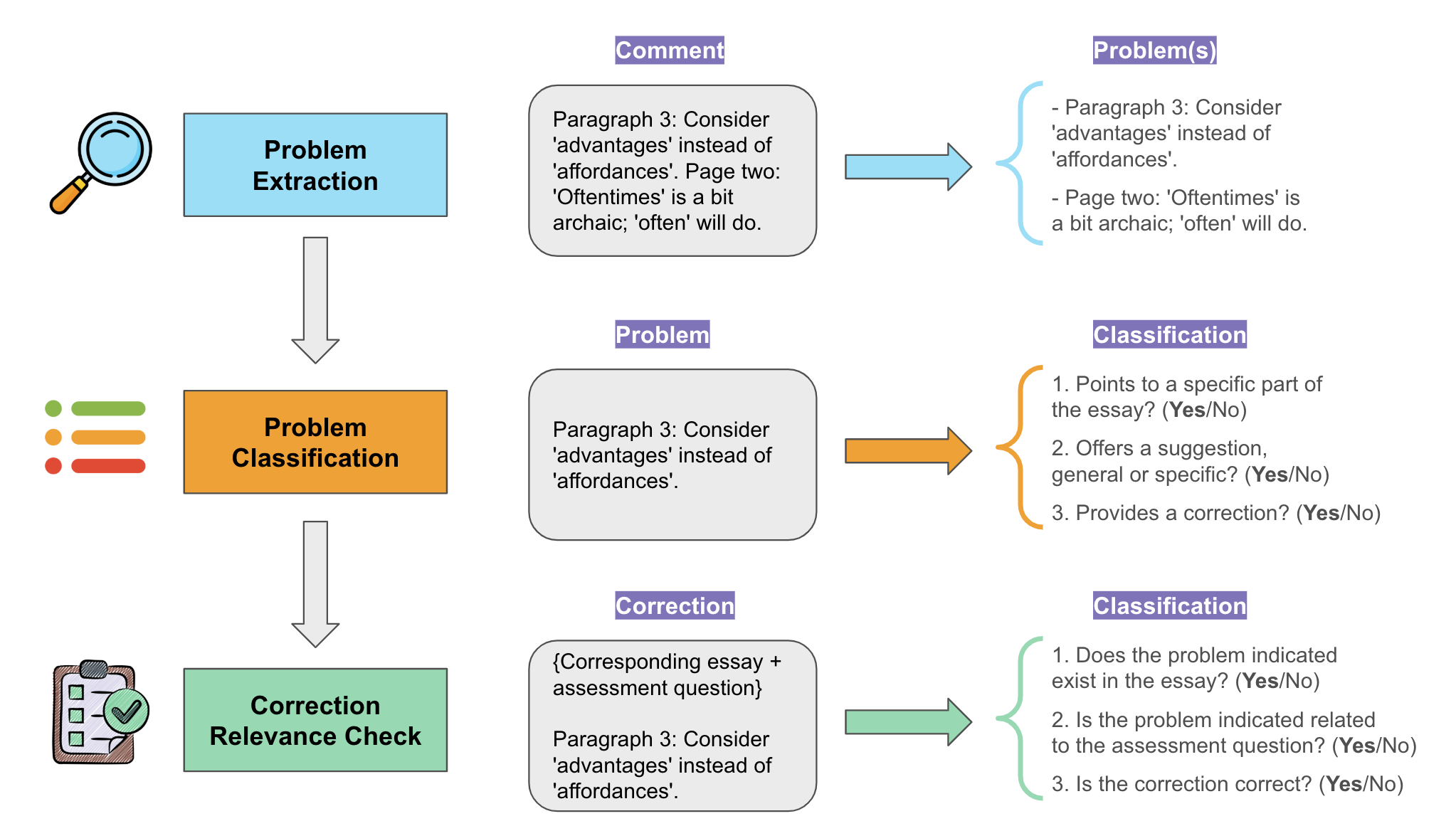
May, 2025: My first-authored paper LLMs can Perform Multi-Dimensional Analytic Writing Assessments: A Case Study of L2 Graduate-Level Academic English Writing has been accepted to ACL 2025 (Main).
-
Feb, 2025: I advanced to PhD candidacy after passing my second qualifying paper.
-
Aug, 2024: I received the Junior Researcher Award from the Institute for Advanced Computational Science at Stony Brook University.
-
May, 2024: I started working for the Home Depot as a Data Scientist intern where I developed various LLM-based systems for topic modeling, classification, and validation. See this blog post for details.
-
June, 2023: I became a trainee for the Bias-NRT (National Science Foundation Research Traineeship) program at Stony Brook University,
-
Aug, 2022: I started my PhD in Computational Linguistics at Stony Brook University.









Blogs
2018
Dec 5
—
从叶芝的《丽达与天鹅》看“诗之美”
Dec 1
—
寂寞和希望:铁屋中的呐喊
Jun 1
—
福建古田教案交涉经过简述
May 25
—
否定词“没”“没有”词汇语法化历程新探——兼论现代汉语否定词系统的形成
May 15
—
De“的、地、得”字短语刍议
Apr 30
—
我见麓山多妩媚
Jan 15
—
关于“的”的几点思考
Jan 14
—
文学自觉与自我实现 ——《我们的祖先》三部曲中现代人的自我意识
2017
Dec 31
—
孔子生平自述的重新解释——兼论“五十而知天命,六十而耳顺”的人生含义
Dec 30
—
《中国歌谣集成•福建卷•福州市分卷》札记
Dec 25
—
《菊与刀》与文化模式研究
Dec 21
—
《理想国》第七卷简括
Nov 21
—
《理想国》第六卷简括
Nov 20
—
形式的意味自何来
Nov 15
—
祖考皇矣
Oct 31
—
《理想国》第五卷简括
Oct 15
—
《理想国》第四卷简括
Oct 14
—
何思何虑,勿助勿忘
Oct 1
—
《理想国》第三卷简括
Jun 30
—
现代化视角下的湖南时务学堂“新旧之争”
Jun 26
—
试论贝卡利亚的死刑思想
May 31
—
白鹿原里的乡土中国——长篇小说《白鹿原》的社会学分析
May 26
—
《论犯罪与刑罚》是怎么写的
May 23
—
The invincible fear of uncertainty
May 10
—
岳麓书院祭孔大典祭文
Apr 12
—
记朱晓农先生的一场讲座
Mar 13
—
On Virtue and Knowledge of Socrates
2016
Nov 14
—
与严翼相教授登岳阳楼
Oct 15
—
从心所欲,不逾矩——情欲与伦理的和解式
Oct 10
—
乌云的银边
Sep 10
—
“有教无类”释义的再探讨
Jun 23
—
莎菲女士是什么样的女人?
Jun 1
—
渊明评传
Apr 13
—
试论《新著国语文法》的“句本位”思想
2015
Dec 1
—
论屈原人格--从屈原的优越感与自卑感说起
Nov 24
—
我看林致远之死
Nov 1
—
“有教无类”释义的再探讨
Oct 28
—
传递网络正能量 争做校园好网民
Oct 15
—
浅谈《沈从文的后半生》
Oct 1
—
重耳见寺人披
Sep 1
—
乌合之众
Feb 1
—
研究性学习
